VecTcl
Performance improvement by compilation to native code
Performance improvement by compilation to native code
Vector expressions can be compiled to native code, if the type of the input variables
is known at compile time. As part of the experiments to provide a JIT compiler for VecTcl,
a compiler has been developed under the jit branch in the repository which compiles vprocs
into C code. Only a limited subset of VecTcl is supported at the moment (no slices or indexes,
no for loops, unary expressions and reductions), and the type of the arguments must be given
at compile time. These limitations will later be lifted, if the scheme proves to be
successful.
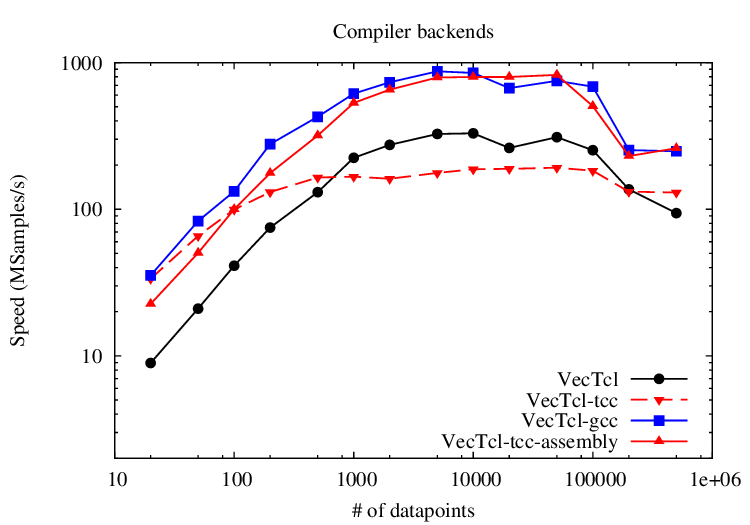
For benchmarking purposes, two functions were compiled and benchmarked using this compiler. The first example is a classic showcase to demonstrate the speed difference of compiled vs. interpreted code in vector languages
jitproc square_tcc {{x {double n}} {y {double n}}} {
x.*x+y.*y+x.*y
}This code was compiled using the standard VecTcl compiler, which compiles to Tcl
(vproc), marked by the black line in the graph. The code was also compiled by jitproc,
which compiles into C and passes the code to tcc4tcl. The auto-generated code was further
passed to gcc to compile a loadable dynamic library, and a
manually optimized inner loop was created using inline assembly in the tcc compiled version
(VecTcl-tcc-assembly)
Up to a vector length of 1000, all native code generation paths significantly outrun the Tcl backend, by avoiding the costs of invoking the VecTcl library functions via the bytecode interpreter. Until 100,000 data points, the tcc compiled expressions are slightly slower than the Tcl versions, which is due to the better optimization of the ahead-of-time compiler (gcc) during compilation of VecTcl. For even larger arrays, the generated temporaries of the Tcl backend exhaust the L3 cache of the machine, and tcc wins over the Tcl backend.
In all cases, the gcc compiled version wins by a large margin. The difference between tcc and gcc is mainly due to failing register allocation in the tcc code. The gcc compiled inner loop runs completely inside the SSE2 registers, whereas tcc spills all variables to memory after each statement. An improvement without the use of an external compiler could be done using the OIL runtime compiler ORC for just the inner loop. The achievable performance by this combination is predicted from the inline assembly experiment (VecTcl-tcc-assebly), where the inner hot loop was created using manual insertion of SSE2/x86_64 opcodes into the tcc output. The result is as fast as the gcc compiled version, while most part of the boilerplate code for setting up the arrays, error handling and interfacing with Tcl is still handled by tcc. To achieve the same performance out of the C backend, a better optimizing JIT compiler backend would be needed such as LLVM instead of tcc. That would also allow calling transcendental functions insisde the loop, which is impossible in ORC.