VecTcl
Memory bandwidth benchmark
Memory bandwidth benchmark
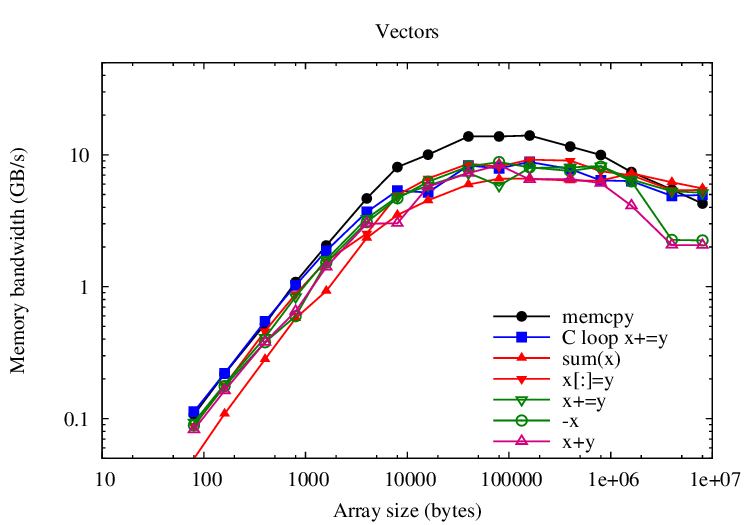
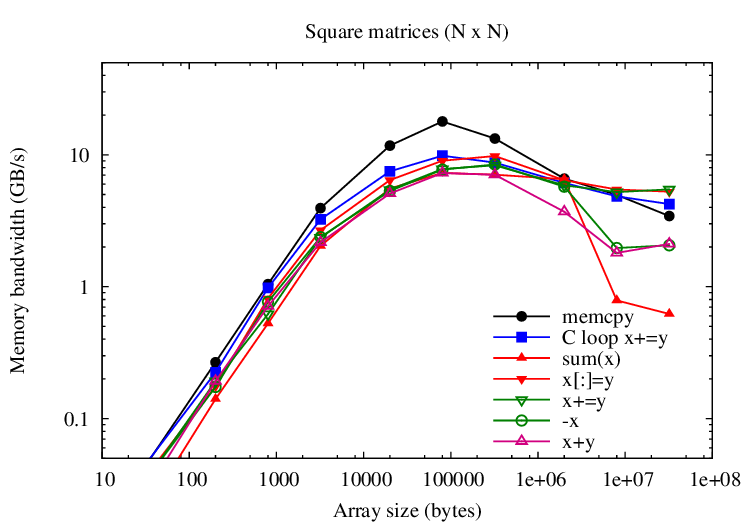
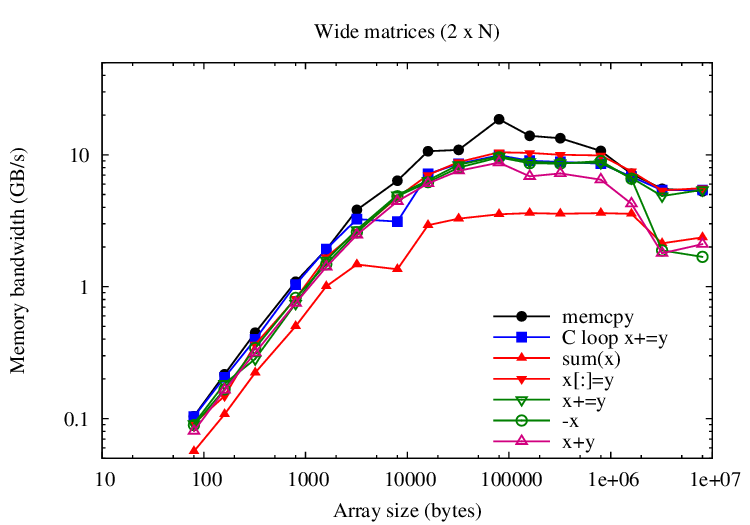
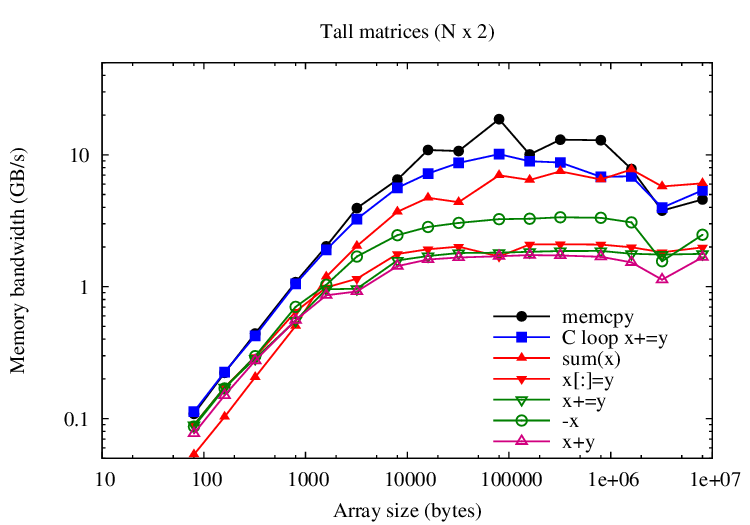
Adding to large arrays is mostly limited by memory bandwidth; this
microbenchmark compares the speed of various operations against memcpy and
a simple C-coded loop that adds to vectors. memcpy outperforms the C-coded loop by a
factor of 2. VecTcl assignment operators (i.e., x+=y) should ideally approach the C-coded loop. For
vectors, we are almost there. Tall matrices are worst. Overall, reductions (i.e., sum(x))
score lowest.